Download Solved Assignments 2017-2018, Solved Question Papers
Best Answers from Yahoo.com, Quora.com, Stackoverflow.com, Ignou.ac.in, Solved Assignments, Solution to any question
A coupling is a mechanical element part that connects two shafts together to accurately transmit the power from the drive side to the driven side while absorbing the mounting error (misalignment), etc. of the two shafts.
Coupling in the machine industry is interpreted as “a part that connects two shafts together”, and is generally called “coupling”, “shaft coupling” or “joint”
A decision support system (DSS) is a computerized program used to support determinations, judgments, and courses of action in an organization or a business. A DSS sifts through and analyzes massive amounts of data, compiling comprehensive information that can be used to solve problems and indecision-making.
Typical information used by a DSS includes target or projected revenue, sales figures or past ones from different time periods, and other inventory- or operations-related data.
A data dictionary is a file or a set of files that contains a database's metadata. The data dictionary contains records about other objects in the database, such as data ownership, data relationships to other objects, and other data.
The data dictionary is a crucial component of any relational database. It provides additional information about relationships between different database tables, helps to organize data in a neat and easily searchable way, and prevents data redundancy issues.
Ironically, because of its importance, it is invisible to most database users. Typically, only database administrators interact with the data dictionary
User interface (UI) design is the process designers use to build interfaces in software or computerized devices, focusing on looks or style. Designers aim to create interfaces which users find easy to use and pleasurable. UI design refers to graphical user interfaces and other forms—e.g., voice-controlled interfaces
Designing User Interfaces for Users
User interfaces are the access points where users interact with designs. They come in three formats:
Graphical user interfaces (GUIs)—Users interact with visual representations on digital control panels. A computer’s desktop is a GUI.
Voice-controlled interfaces(VUIs)—Users interact with these through their voices. Most smart assistants—e.g., Siri on iPhone and Alexa on Amazon devices—are VUIs.
Gesture-based interfaces—Users engage with 3D design spaces through bodily motions: e.g., in virtual reality (VR) games.
To design UIs best, you should consider:
Users judge designs quickly and care about usability and likeability.
They don’t care about your design, but about getting their tasks done easily and with minimum effort.
Your design should therefore be “invisible”: Users shouldn’t focus on it but on completing tasks: e.g., ordering pizza on Domino’s Zero Click app.
So, understand your users’ contexts and task flows (which you can find from, e.g., customer journey maps), to fine-tune the best, most intuitive UIs that deliver seamless experiences.
UIs should also be enjoyable (or at least satisfying and frustration-free).
When your design predicts users’ needs, they can enjoy more personalized and immersive experiences. Delight them, and they’ll keep returning.
Where appropriate, elements of gamification can make your design more fun.
UIs should communicate brand values and reinforce users’ trust.
Good design is emotional design. Users associate good feelings with brands that speak to them at all levels and keep the magic of pleasurable, seamless experiences alive.
UI vs. User Experience (UX) Design
Often confused with UX design, UI design is more concerned with the surface and overall feel of a design. UI design is a craft where you the designer build an essential part of the user experience. UX design covers the entire spectrum of the user experience. One analogy is to picture UX design as a car with UI design as the driving console.
How to make Great UIs
To deliver impressive GUIs, remember—users are humans, with needs such as comfort and a limit on their mental capacities. You should follow these guidelines:
Make buttons and other common elementsperform predictably (including responses such as pinch-to-zoom) so users can unconsciously use them everywhere. Form should follow function.
Maintain high discoverability. Clearly label icons and include well-indicated affordances: e.g., shadows for buttons.
Keep interfaces simple (with only elements that help serve users’ purposes) and create an “invisible” feel.
Respect the user’s eye and attention regarding layout. Focus on hierarchy and readability:
Use proper alignment. Typically choose edge (over center) alignment.
Draw attention to key features using:
Color, brightness and contrast. Avoid including colors or buttons excessively.
Text via font sizes, bold type/weighting, italics, capitals and distance between letters. Users should pick up meanings just by scanning.
Minimize the number of actions for performing tasks but focus on one chief function per page. Guide users by indicating preferred actions. Ease complex tasks by using progressive disclosure.
Put controls near objects that users want to control. For example, a button to submit a form should be near the form.
Keep users informed regarding system responses/actions with feedback.
Use appropriate UI design patterns to help guide users and reduce burdens (e.g., pre-fill forms). Beware of using dark patterns, which include hard-to-see prefilled opt-in/opt-out checkboxes and sneaking items into users’ carts.
Maintain brand consistency.
Always provide next steps which users can deduce naturally, whatever their context.
Joint Application Development (JAD) is a process used to collect business requirements while developing new information systems for a company. The JAD process may also include approaches for enhancing user participation, expediting development and improving the quality of specifications. The intention of a JAD session is to pool in subject matter expert’s/Business analyst or IT specialist to bring out solutions.
A Business analyst is the one who interacts with the entire group and gathers the information, analyses it and brings out a document. He plays a very important role in JAD session.
Use of a JAD Session
JAD sessions are highly structured, facilitated workshops that bring together customer decision makers and IT staff to produce high quality deliverables in a short period.
In other words, a JAD Session enables customers and developers to quickly come to an agreement on the basic scope, objectives and specifications of a project or in case, not come to an agreement which means the project needs to be re-evaluated.
Simply put, JAD sessions can
Simplify − It consolidates months of meetings and phone calls into a structured workshop.
Identify − Issues and participants
Quantify − Information and processing needs
Clarify − Crystallize and clarify all requirements agreed upon in the session.
Unify − The output from one phase of development is input to the next.
Satisfy − The customers define the system; therefore, it is their system. Shared participation brings a share in the outcome; they become committed to the systems success.
Participants in a JAD Session
The participants involved in a JAD session are as follows −
Executive Sponsor
An executive sponsor is the person who drivers the project ─ the system owner. They normally are from higher positions and are able to make decisions and provide necessary strategy, planning and direction.
Subject Matter Expert
These are the business users and outside experts who are required for a successful workshop. The subject matter experts are the backbone of the JAD session. They will drive the changes.
Facilitator
He chairs the meeting; he identifies issues that can be solved as part of the meeting. The facilitator does not contribute information to the meeting.
Key Users
Key users or also called as super users in some instances have been used interchangeable and differs from company to company still. Key users are generally the business users who are more tightly aligned to the IT project and are responsible for the configuration of profiles of their team members during the projects.
For Example: Suppose John is a key user and Nancy, Evan are users of a SAP system. In this instance, Nancy and Evan does not have access to change the functionality and profile whereas John being a Key user has access to edit profile with more authorizations.
The JAD approach, in comparison with the more traditional practice, is thought to lead to faster development times and greater client satisfaction, because the client is involved throughout the development process. In comparison, in the traditional approach to systems development, the developer investigates the system requirements and develops an application, with client input consisting of a series of interviews
/* main( ) function */ void main() { int choice, num; while(1) { printf("\n Press 1 for insert number"); printf("\n Press 2 for delete number"); printf("\n Press 3 for display list"); printf("\n Press 4 for exit"); printf("\n Enter your choice : "); scanf("%d",&choice); switch(choice) { case 1: printf("\n Enter the number : "); scanf("%d",&num); insertNode(num); break; case 2: if(head == NULL) printf("\n List is blank !"); else { printf("\n Enter the number : "); scanf("%d",&num); deleteNode(num); } break; case 3: displayList(); break; case 4: exit(0); default: printf("\n\n\n Wrong Input"); } } }
/* Insert number into the list */ void insertNode(int n) { /* Check whether the list is blank or not */ /* If blank then create a memory into head variable and place the number into it */ if(head == NULL) { head = (NODE *) malloc(sizeof(NODE)); head->number = n; head->previous = head; head->next = head; } else { /* If the list is not blank then create a memory into temp variable, place the number into it and add this memory to the end of the list */ temp = (NODE *) malloc(sizeof(NODE)); temp->number = n; p = head; while(p->next != head) p = p->next; p->next = temp; temp->previous = p; temp->next = head; head->previous = temp; } }
/* Delete a particular number from the list */ void deleteNode(int n) { int found = 0; /* Check whether the list contain only one element or not */ if(head->next == head && head->previous == head) { if(head->number == n) { found = 1; head = NULL; } } else /* Check whether the number found into the first-memory (head) of the list or not ? */ if(head->number == n) { temp = head; head = head->next; head->previous = temp->previous; temp->previous->next = head; found = 1; } else { p = head->next; while(p != head) { if(p->number == n) { p->next->previous = p->previous; p->previous->next = p->next; found = 1; break; } p = p->next; } } if(found == 0) printf("\n Element not found !"); }
/* Display list elements */ void displayList() { /* Check whether the list is blank or not */ if(head == NULL) printf("\n List is blank !"); else { p = head; while(p->next != head) { printf("\t%d",p->number); p = p->next; } printf("\t%d",p->number); } }
B-Tree is a specialized m-way tree that can be widely used for disk access. A B-Tree of order m can have at most m-1 keys and m children. One of the main reason of using B-Tree is its capability to store large number of keys in a single node and large key values by keeping the height of the tree relatively small.
Properties of B-Tree -
A B-Tree is defined by the term minimum degree ‘t’
Every node except root must contain at least (t – 1) keys. Root may contain minimum 1 key.
All nodes (including root) may contain at most (2t – 1) keys.
Number of children of a node is equal to the number of keys in it plus 1.
All keys of a node are sorted in increasing order. The child between two keys k1 and k2 contains all keys in the range from k1 and k2.
B-Tree Insertion
Let us understand the algorithm with an example tree of minimum degree ‘t’ as 3 and a sequence of integers 10, 20, 30, 40, 50, 60, 70, 80 and 90 in an initially empty B-Tree.
Initially root is NULL. Let us first insert 10.
Let us now insert 20, 30, 40 and 50. They all will be inserted in root because maximum number of keys a node can accommodate is 2*t – 1 which is 5.
Let us now insert 60. Since root node is full, it will first split into two, then 60 will be inserted into the appropriate child.
Let us now insert 70 and 80. These new keys will be inserted into the appropriate leaf without any split.
Let us now insert 90. This insertion will cause a split. The middle key will go up to the parent.
/* Insert operation and height count */ void insertNode(int n) { if(root == NULL) { root = (NODE *) malloc(sizeof(NODE)); root->number = n; root->leftchild = NULL; root->rightchild = NULL; } else { child = (NODE *) malloc(sizeof(NODE)); child->number = n; child->leftchild = NULL; child->rightchild = NULL; p = root; while(p != NULL) { /* If number <= root value then goto the left side */ if(n <= p->number) { if(p->leftchild == NULL) { p->leftchild = child; count++; break; } else p = p->leftchild; } /* If number > root value then goto the right side */ if(n > p->number) { if(p->rightchild == NULL) { p->rightchild = child; count++; break; } else p = p->rightchild; } count++; } } }
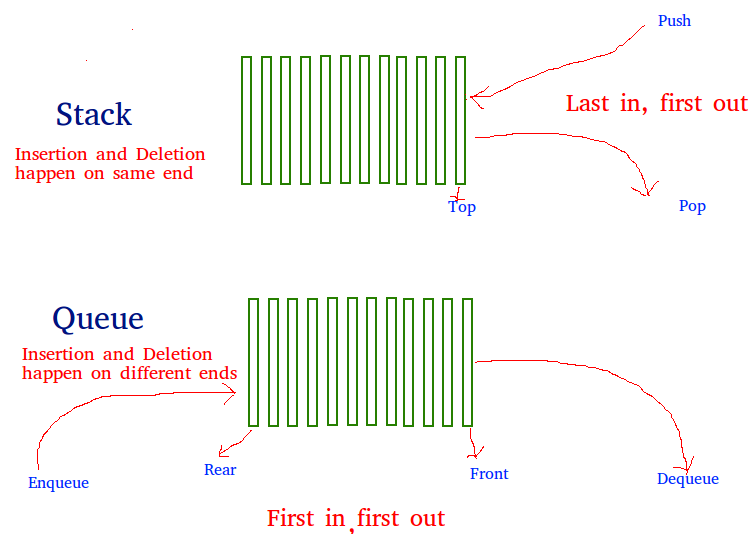
The problem is opposite of this post. We are given a stack data structure with push and pop operations, the task is to implement a queue using instances of stack data structure and operations on them.
A queue can be implemented using two stacks. Let queue to be implemented be q and stacks used to implement q be stack1 and stack2. q can be implemented in two ways:
Method 1 (By making enQueue operation costly) This method makes sure that oldest entered element is always at the top of stack 1, so that deQueue operation just pops from stack1. To put the element at top of stack1, stack2 is used
enQueue(q, x):
While stack1 is not empty, push everything from stack1 to stack2.
Push x to stack1 (assuming size of stacks is unlimited).
Push everything back to stack1.
Here time complexity will be O(n)
deQueue(q):
If stack1 is empty then error
Pop an item from stack1 and return it
Here time complexity will be O(1)
// CPP program to implement Queue using // two stacks with costly enQueue() #include <bits/stdc++.h> usingnamespacestd; structQueue { stack<int> s1, s2; voidenQueue(intx) { // Move all elements from s1 to s2 while(!s1.empty()) { s2.push(s1.top()); s1.pop(); } // Push item into s1 s1.push(x); // Push everything back to s1 while(!s2.empty()) { s1.push(s2.top()); s2.pop(); } } // Dequeue an item from the queue intdeQueue() { // if first stack is empty if(s1.empty()) { cout << "Q is Empty"; exit(0); } // Return top of s1 intx = s1.top(); s1.pop(); returnx; } }; // Driver code intmain() { Queue q; q.enQueue(1); q.enQueue(2); q.enQueue(3);